【神麻人智】选择偏倚对基于深度学习的术中低血压预测模型性能的影响:使用公开数据库真实世界样本的研究
时间:2025-09-08 12:15:45 来源 网络 作者:网络
摘要
背景: 已有模型可以基于动脉压波形预测术中低血压。然而,用于模型开发和验证的数据集中的选择偏倚可能影响模型性能。本研究旨在评估选择偏倚对基于深度学习(DL)的模型和仅使用平均动脉压(MAP)输入的模型(MAP-only model)预测性能的影响。
方法: 我们使用VitalDB公开数据集。低血压事件定义为MAP<65 mmHg持续1分钟。对于“有偏数据集”,非低血压事件需满足:(a) 位于MAP>75 mmHg持续超过30分钟的非低血压期的中心;(b) 距任何低血压事件至少20分钟以上。对于“无偏数据集”,除输入片段已出现低血压事件的样本外,其他样本均纳入。比较了两类模型的每小时报警次数和阳性预测值。
结果: DL模型总体表现优于MAP-only模型。在预测术中低血压(事件前5分钟)时,使用无偏测试集和有偏测试集的DL模型分别产生18.1次/小时和10.8次/小时的报警(P<0.001),阳性预测值为0.068和0.937(P<0.001)。
结论: 在无偏数据集上,两种模型预测性能均下降。虽然DL模型在统计学上优于MAP-only模型,但两者之间的临床意义差异不大。临床医生在验证和应用低血压预测模型时应考虑选择偏倚的潜在影响。
研究要点
-
深度学习模型可基于动脉压波形预测低血压。
-
开发与验证预测模型需严谨,以确保临床可用性。
-
数据集的选择偏倚可能影响模型性能。
-
本研究使用公开数据库评估选择偏倚对模型预测性能的影响。
-
在无偏数据集测试时,两种模型性能均显著下降。
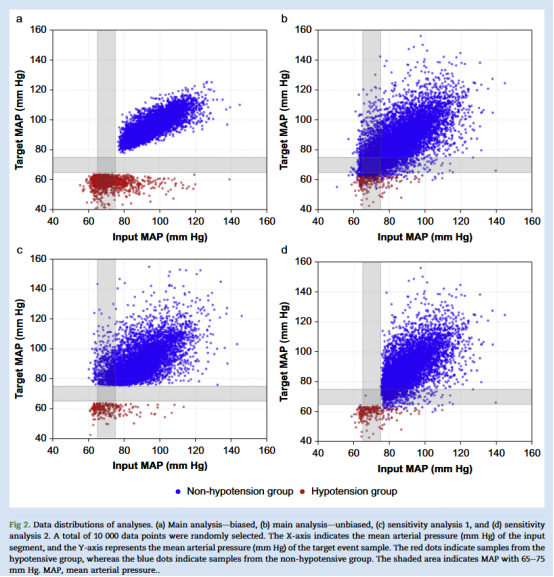
在非心脏手术中常见低血压,与心肌损伤、急性肾损伤、中风及死亡等不良结局相关。尽管早期识别和及时干预有助于降低风险,但低血压预测仍具挑战性。预测低血压已有多种机器学习方法(如逻辑回归、朴素贝叶斯、支持向量机),其中商业化的 Acumen™ 低血压预测指数(HPI)(Edwards Lifesciences,美国加州尔湾)利用动脉压波形23项特征预测低血压,因此受到关注。然而,近期研究指出其开发和验证中的训练数据存在选择性偏倚:所有“非低血压”样本均来自平均动脉压(MAP)连续≥30分钟高于75 mm Hg且距MAP<65 mm Hg低血压事件≥20分钟的时段(Fig.1),使非低血压组的输入和目标MAP值均为75 mm Hg(Fig.2)。这种基于未来MAP值排除模糊样本的策略可能高估模型性能,降低临床适用性。研究还表明,排除MAP 65–75 mm Hg区间样本时,简单MAP线性外推也能取得优异预测效果,且HPI与基于MAP预测在真实临床环境中表现相当。虽然已有学者提出基于深度学习(DL)的预测模型,但其有效性仍待严格验证。本研究旨在评估选择性偏倚对DL预测模型及仅基于MAP的MAPonly模型预测性能的影响。
方法
数据来源与伦理
数据来自VitalDB,包含首尔大学医院2016年8月至2017年6月期间6388例全麻手术患者的高保真生命体征数据。研究通过伦理审批并注册(NCT02914444)。
纳入标准
所有手术病例均纳入,排除无动脉压波形监测、年龄<19岁、体重<30或>140 kg、身高<135或>200 cm,以及移植、主动脉或动脉瘤相关手术、脊柱手术、镇静麻醉病例。最终纳入的手术病例被分为三类数据集:训练集(72%)、验证集(18%)和测试集(10%)。为提高结果可靠性,测试集采用十折交叉验证,每例手术均在测试集中使用一次。该方法避免了因某类手术集中在单一测试集中而导致术中低血压发生率差异造成的结果偏倚。
数据选择与预处理
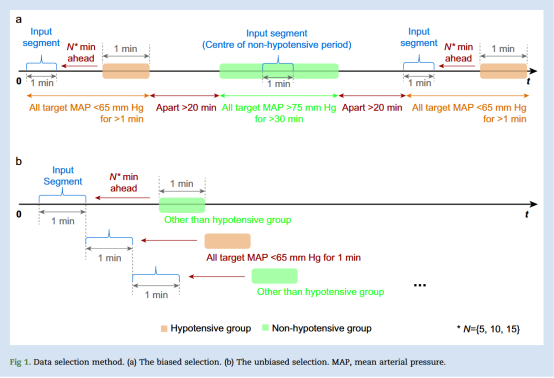
本研究构建了两个数据集以重现选择性偏倚并评估其影响。对于“偏倚数据集”,我们根据Hatib等人的研究将“低血压事件”定义为平均动脉压(MAP)<65 mm Hg持续1分钟;“非低血压事件”则需满足:(a)位于“非低血压时段”的中心,且MAP连续>30分钟高于75 mm Hg;(b)距离任何低血压事件至少20分钟。输入片段长度为1分钟。低血压组的输入片段取自低血压事件前5、10或15分钟;非低血压组的输入片段取自非低血压时段的中心(Fig. 1a)。对于“非偏倚数据集”,采用1分钟滑动窗口法,将MAP<65 mm Hg持续1分钟定义为低血压事件,其余窗口均视为非低血压事件(Fig. 1b)。两组数据均经过相同预处理以滤除噪声数据,并排除了出现低血压输入片段(MAP<65 mm Hg持续1分钟)的样本。事件组和输入片段的定义总结见Table 1。

模型构建
构建MAP-only模型和基于卷积神经网络(CNN)的DL模型,以原始1分钟动脉压波形为输入,预测未来5、10或15分钟内低血压事件。模型未使用人口学特征。另构建基于长短期记忆网络(LSTM)的模型用于补充分析。
统计分析
患者人口学特征根据分布正态性(D’Agostino–Pearson检验)分别以均值(标准差)或中位数(四分位数)表示。模型性能指标包括每小时报警次数、阳性预测值(PPV)、特异性、受试者工作特征曲线下面积(AUROC)及精确率-召回率曲线下面积(AUPRC),均基于临床经验在85%灵敏度下计算,同时报告灵敏度0.1–0.9范围内的指标。性能结果以均值表示,并通过1000次自助法计算95%置信区间。模型每小时报警次数和PPV的比较采用Levine检验后配对t检验;AUROC比较采用DeLong检验;模型输出间相关性采用Spearman秩相关分析;P<0.001视为具有统计学意义。基于VitalDB数据集手术类型进行了亚组分析,以评估不同低血压发生率下的选择偏倚影响。
敏感性分析
在偏倚数据集中,非低血压组中MAP为75 mm Hg的所有输入和目标片段均被排除,因为输入片段取自MAP连续>30分钟维持在75 mm Hg以上时段的中心。因此进行了两项敏感性分析:第一,基于非偏倚数据集,排除所有目标MAP低于75 mm Hg的样本;第二,基于非偏倚数据集,排除所有输入MAP在65–75 mm Hg之间的样本。该分析旨在评估在输入或目标阶段引入选择偏倚时性能失真的程度。非低血压组事件定义见Table 1,各分析中数据样本的分布见Fig 2。
结果
研究对象与数据集
在6388例病例中,本研究分析了具有动脉压波形的3091例患者数据。患者在平均3.8小时麻醉过程中经历了约12分钟术中低血压。由于采用10折交叉验证,病例随机分配至训练集和测试集,因此未对训练集与测试集进行特征比较。
模型性能
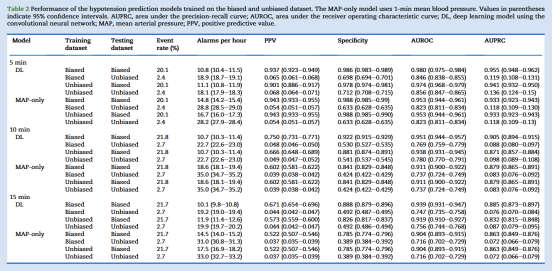
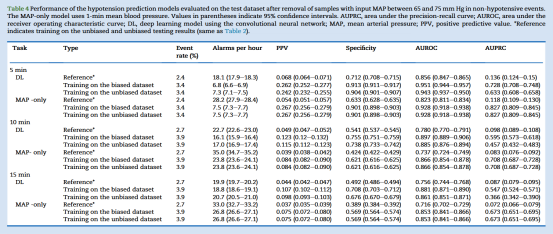
总体而言,深度学习(DL)模型表现优于仅基于MAP的MAP-only模型。在预测术中低血压事件发生前5分钟时,使用非偏倚数据集训练的DL模型每小时报警次数更少(18.1 vs 28.2),阳性预测值(PPV)更高(0.068 vs 0.054),预测提前10和15分钟的结果类似。Table 2显示,无论模型类型或预测窗口长短,用非偏倚测试集评估均导致报警次数增加、PPV下降(Fig. 2a、2b)。例如,DL模型预测提前5分钟时,非偏倚与偏倚测试集结果分别为18.1 vs 10.8次/小时、PPV为0.068 vs 0.937(均P<0.001)。DL模型在非偏倚数据集训练下表现进一步改善,而MAP-only模型在不同训练集间无显著差异。MAP-only模型实现85%灵敏度的最佳MAP阈值分别为75、82、84 mm Hg(提前5、10、15分钟预测),两类训练集间无差异。
敏感性分析
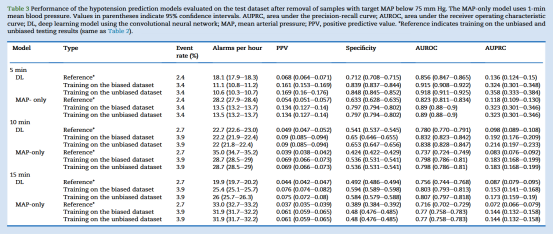
在非偏倚测试集中排除目标MAP曾短暂低于75 mm Hg的样本(Fig. 2c)后,5分钟预测窗口的DL模型每小时报警次数由18.1次降至10.6次,PPV由0.068升至0.169(Table 3)。而排除输入MAP在65–75 mm Hg之间的样本(Fig. 2d)后,报警次数降幅更大(由18.1次降至7.3次),PPV升至0.242(Table 4)。
讨论
本研究旨在评估训练数据选择性偏倚对低血压预测模型的影响。研究基于公开数据库分别训练了深度学习(DL)模型和仅基于MAP的MAP-only模型,并在有无偏倚的数据集上验证性能。结果显示,偏倚测试集可显著夸大模型表现,尤其是PPV:偏倚数据下多数报警为真报警,而非偏倚数据下假报警率极高。这表明先前研究可能高估模型性能。尽管DL模型统计学上优于MAP-only模型,但临床意义有限,两者预测结果高度相关。
敏感性分析发现,排除输入MAP在65–75 mm Hg的样本可明显提高PPV。不同研究的PPV差异与阈值选择和事件发生率有关,一些研究的评估方法可能偏宽松。本研究在尽量减少样本剔除的前提下,从多阈值评估模型性能,并用报警频率和PPV直观反映临床表现。DL模型可从原始波形中提取更多信息,但高假报警率限制了临床应用,低血压病因多样及干预影响是重要原因。公开数据库可为预测模型提供客观验证框架。
本研究局限包括:未纳入专有HPI算法、数据来源单中心、模型结构与采样策略尚可优化、缺乏干预信息和重复采样控制等。总之,偏倚数据集显著影响预测性能评估,DL模型虽优于MAP-only模型,但差异临床意义不大,提示在模型开发与验证中需谨慎处理选择性偏倚问题。
神麻人智述评
以下是对该文的综合述评,重点围绕其结论、临床意义、局限性及未来研究方向展开。
一、研究结论概述
该研究通过对比“有偏”与“无偏”数据集上的模型表现,得出以下核心结论:
1. 选择偏倚显著夸大模型性能:在“有偏数据集”(仅包含MAP持续>75 mmHg且远离低血压事件的样本)上,无论是深度学习模型还是仅基于MAP的基线模型,均表现出极高的阳性预测值(PPV≈0.937)和较低的每小时警报次数(≈10.8次)。然而,在“无偏数据集”(包含所有可用样本)上,PPV骤降至0.068,警报次数上升至18.1次/小时,表明模型在实际临床环境中的预测能力被严重高估。
2. 深度学习模型优于MAP-only模型,但临床差异有限:尽管DL模型在统计学上显著优于仅基于MAP的模型,但两者在无偏测试集上的PPV均极低(DL: 0.068 vs MAP-only: 0.054),提示其临床实用性有限。
3. 敏感度分析揭示偏倚来源:排除输入MAP在65–75 mmHg之间的样本会显著提高PPV,说明输入段的筛选是导致性能高估的主要因素,而非目标事件的筛选。
二、临床意义
1. 对现有预测模型的质疑:研究直接挑战了如HPI(Hypotension Prediction Index)等已商用模型的验证方法,指出其训练和验证过程中可能存在严重的选择偏倚,导致其在实际应用中表现不佳。
2. 提醒临床研究者重视数据质量与代表性:研究强调,模型开发过程中若未考虑真实世界数据的复杂性和连续性(如MAP在65–75 mmHg之间的“灰色地带”),则其外部效度将大打折扣。
3. 推动透明与可重复的研究实践:作者公开了全部代码与数据处理流程,为后续研究提供了可复现的基准,倡导开放科学在医疗AI中的实践。
4. 临床实用性的重新评估:高误报率(低PPV)意味着若将此类模型直接用于临床决策支持,可能导致警报疲劳,反而增加医疗风险。研究提示当前一代低血压预测模型尚未达到可直接临床部署的水平。
三、研究局限性
1. 数据来源单一:仅使用韩国单一中心的VitalDB数据库,人群结构和手术类型有限,限制了模型的泛化能力。
2. 未包含HPI直接对比:由于HPI为商业算法,未能将其纳入比较,使得结论未能直接反驳或支持HPI的实际表现。
3. 未考虑临床干预的影响:数据中未记录低血压发生时的临床干预(如升压药使用),这可能导致模型无法学习到干预对血压变化的调节作用。
4. 模型架构仍有优化空间:作者使用的CNN和LSTM结构较为基础,未进行大量超参数优化或集成学习等进阶方法,可能未充分发挥DL模型的潜力。
5. 未处理患者内相关性:同一患者多次采样可能导致数据不独立,可能影响模型评估的稳定性。
四、未来研究方向
1. 多中心外部验证:应在不同人群、不同手术类型、不同医疗中心的数据上进行验证,以评估模型的泛化能力和鲁棒性。
2. 纳入临床干预信息:未来研究应整合药物使用、液体管理等干预数据,构建更接近真实临床决策过程的预测模型。
3. 改进模型架构与训练策略:尝试更先进的神经网络结构、多任务学习、或引入生理先验知识,以提升模型性能。
4. 开发可解释AI工具:通过注意力机制、SHAP值等方法,揭示模型预测的依据,增强临床信任度。
5. 推动真实世界前瞻性试验:在真实手术环境中进行前瞻性测试,评估模型对临床结局(如AKI、心肌损伤)的实际影响
6. 探索动态阈值与个性化预测:根据不同患者基线血压、手术类型等因素动态调整预测阈值,提升个性化水平。
该研究呼吁学界在模型开发与验证中更加注重数据的代表性和透明度,并推动更具临床意义的评估标准。未来研究需在多中心数据、临床干预整合、模型可解释性等方面进一步深入,才能真正实现AI在围术期低血压预测中的临床转化。

