眼科疾病防治面临的最大挑战之一是多模态信息的整合不足。临床诊断时常依赖多种成像方式,如彩色眼底照相(CFP)、光学相干断层扫描(OCT)、荧光素眼底血管造影(FFA)以及眼底自发荧光(FAF)等,每种模态提供结构和功能的独特视角。然而,现有AI模型多聚焦于单一模态,难以充分利用多模态带来的互补效应,且面对罕见病种时因长尾分布导致训练数据稀缺,模型泛化能力弱。基础模型(foundation model)概念在医学影像分析中风靡,模型通过大规模数据无监督或弱监督预训练,学习抽象且通用的表示。然而,目前眼科领域还缺乏能在多个模态上实现图像-语言语义对齐,保障模态间互操作性和跨任务转移性的基础模型。EyeCLIP正是在此背景下一种创新方案。
近期,发表在npj Digital Medicine上的研究中,香港理工大学及多国机构的研究团队提出了一款名为EyeCLIP的多模态视觉-语言基础模型,利用超过277万张涵盖11种临床眼科成像模态的多中心数据,并结合临床文本信息,实现了多视角、多模态眼科数据的统一理解,提升了包括多种眼病分类、视觉问答和跨模态信息检索等多项任务的性能,尤其在数据稀缺的少样本场景下表现优异。此项研究为基础医学人工智能模型向临床真实环境的转化应用提供了重要参考。

本研究收集了我国227家医院的2,777,593张多模态眼科影像(涵盖CFP、FFA、ICGA、OCT等11种模态),及11,180份临床诊断报告,涉及128,554名患者。针对临床文本较长且多样,研究团队构建了医学关键词映射字典,将报告自动转换为结构化的分层语义标签。模型训练结合三种关键技术:
- 自监督重建任务,使用掩码自动编码的方式增强特征表达的稳健性。
- 跨模态图像对比学习,实现不同成像模态间的特征对齐。
- 影像-文本对比学习,促进视觉表征与临床语义的深度融合。
EyeCLIP采用统一图像编码器,避免了多模态各自为阵的弊端,提升了模型的可扩展性与部署便利性(详见图1)。通过上述训练策略,模型能有效利用临床中普遍存在的部分对齐、多模态不完整数据,充分挖掘多视角结构信息与文本上下文。
研究结果
1,多中心多模态数据训练及模型设计
EyeCLIP在多地区、多医院采集的广泛数据基础上形成,模型设计使其能支持零样本、少样本以及监督学习工作流。利用特征融合与对比学习,模型显著提升了跨模态诊断准确率和多任务泛化能力。

图:EyeCLIP预训练及多中心多模态数据整合流程图
2,零样本和少样本眼科疾病分类表现
在9个公开眼科单模态数据集上,EyeCLIP的零样本分类AUC均显著高于通用CLIP、医学领域BioMedCLIP与同领域RETFound(P<0.001)。包括糖尿病视网膜病变、青光眼等多种疾病均显示优异识别能力。
少样本学习中,通过使用每类1至16个训练样本微调,EyeCLIP展现了显著更强的数据效率,准确率大幅优于竞品模型。
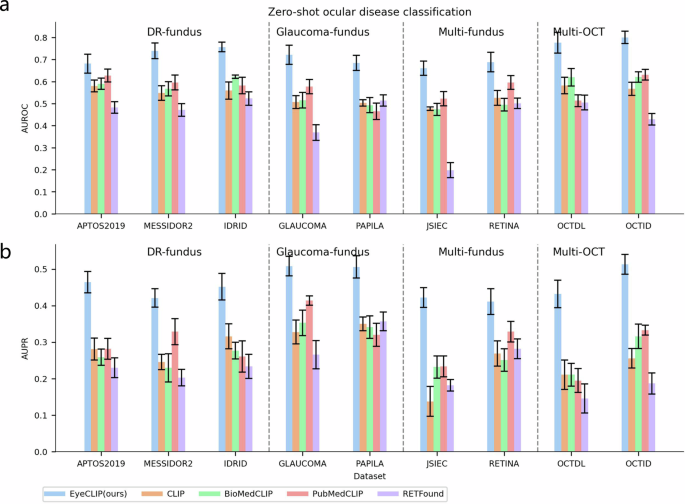
图:EyeCLIP零样本分类性能展示(AUROC及AUPR)
3,罕见病种分类
利用Retina Image Bank中17种罕见眼病子集,EyeCLIP在全训练数据下均领先其他模型,准确识别度最高,显示其对临床长尾问题的突破。
4,完整数据监督训练
在11个多模态公共数据集上,尤其是眼底血管造影AngioReport和多模态Retina Image Bank,EyeCLIP均取得最高或持平的AUC,充分展现应用广泛性。
消融实验强调图像自监督重建在保留多模态结构语义一致性上的关键作用。
5,系统性疾病预测
EyeCLIP利用眼部图像有效预测中风、认知障碍、帕金森病和心肌梗死,均超越现有模型,表明模型对眼部与全身疾病之间的关联能有效挖掘,有望提升全生命周期健康管理。
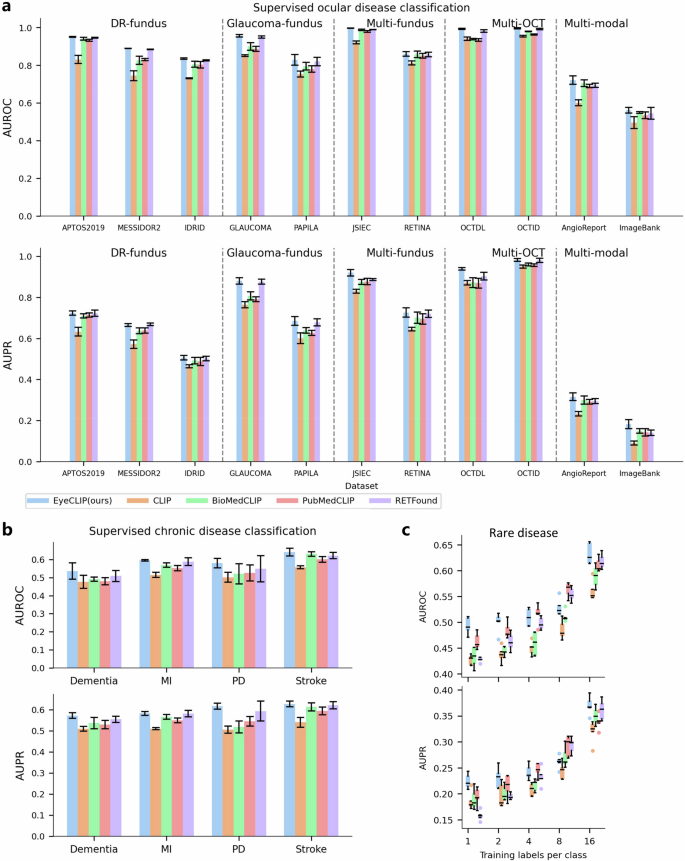
图:EyeCLIP在眼科疾病、系统性疾病及罕见病分类任务中的全数据监督训练结果
6,跨模态检索与视觉问答
零样本跨模态检索任务中,EyeCLIP在AngioReport和Retina Image Bank数据集上Recall@K值均显著优于BioMedCLIP,支持基于影像检索诊断报告或反向检索的多样化应用。
在OphthalVQA视觉问答任务中,以少量训练数据微调,EyeCLIP结合大型语言模型(Llama 2-7b)实现最佳的问答精度和语言一致性,体现了自然语言交互助力临床决策的潜力。
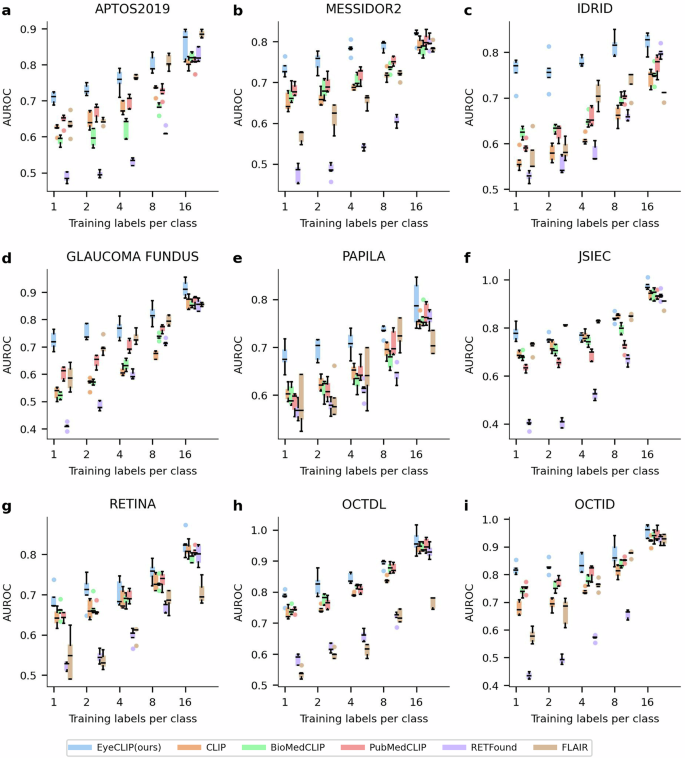
图:EyeCLIP少样本分类表现跨多个眼科公开数据集
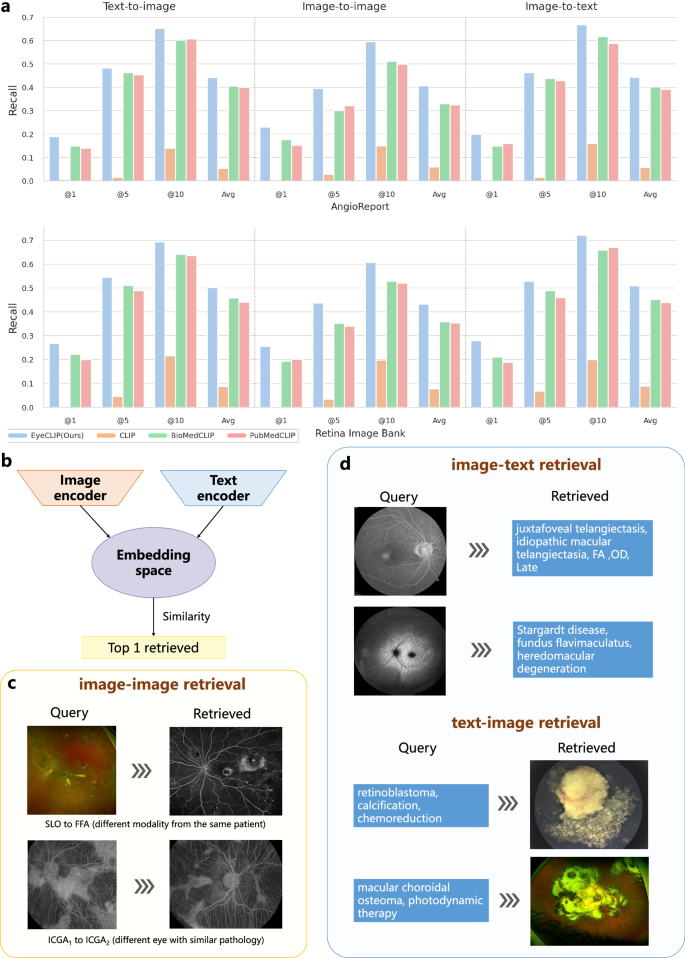
图:EyeCLIP零样本跨模态检索性能及示例
7,病变区域可视化分析
通过文本-图像补丁相似度热力图,模型能对应疾病描述精准聚焦相关病灶区域,增强了模型的可解释性和临床信赖度。
研究价值与意义
这项工作开创性地提出了一种多模态集成且具语言理解能力的眼科基础模型EyeCLIP,兼具强大泛化能力和临床实用价值。它突破了单一模态或分离编码器模式的限制,通过整合多源、多模态的眼科图像与专业诊断文本,实现了视觉语义的深度融合,提升了对复杂病例和罕见病种的诊断能力。模型不仅能精确完成眼科疾病分类,还能预测严重的系统疾病,打通视觉数据与语言信息的桥梁。其零样本和少样本高效学习能力,降低了对大规模标注数据的依赖,极大缩短了模型部署和临床推广周期。此外,EyeCLIP对不完全对齐的多模态医疗数据有高适应性,为其他医学领域开发多模态基础模型提供了范本。
尽管表现卓著,EyeCLIP也面临如数据种族代表性不足、二维影像信息局限、推理速度与模型可解释性需进一步提升等挑战。未来通过纳入多民族均衡数据、利用三维影像信息及模型轻量化技术,尤其结合电子健康记录等系统数据,EyeCLIP有望成为覆盖眼科及跨学科领域的智能诊断助理,辅助医生实现精准、高效、个性化医疗。
原始出处
Shi D, Zhang W, Yang J, Huang S, Chen X, Xu P, Jin K, Lin S, Wei J, Yusufu M, Liu S, Zhang Q, Ge Z, Xu X, He M. A multimodal visual–language foundation model for computational ophthalmology. npj Digital Medicine. 2025;8:381. doi:10.1038/s41746-025-01772-2